
AIVOCO / FRONTIER NOTES: From Context Engineering to Weight Management
The future of AI isn't about giving the model a longer note; it's about letting it learn on the job. A deep dive into the architecture of Continual Learning APIs.

Every employee who has ever started a new job was bad at it on day one. They got better not because they became more intelligent overnight, but because they accumulated experience: the client who prefers email over calls, the report format leadership actually reads, the edge case that broke things last quarter. That accumulation, repeated daily, is what eventually turns a new hire into someone the company can trust with judgment calls.
Until now, AI models could not do this. Every API call to a large language model starts from zero. The model is, in a very real sense, permanently new on the job. A new generation of APIs is changing that, and the change is bigger than a feature update. It is a shift in what an AI model fundamentally is.
The API Pattern Everyone Already Knows
Over the past three years, a single API shape has become the default way the world builds with AI. Send a request with some content, get a response back. That pattern, popularized by OpenAI, is now the default blueprint for AI integration.
Roughly four in ten new AI-enabled software products built in 2025 were reported to rely on this exact API shape. The request and response structure has become as familiar to developers as a standard web request. It works well for what it was built for—answering questions, classifying text, drafting a first pass—but it has one defining trait: Statelessness. Close the connection, and the model forgets you existed.
The Limit of a Model That Never Remembers
Stateless is fine for a calculator. It is a real constraint for anything resembling a colleague. Today, developers work around the model's amnesia with engineering effort: stuffing prior context back into every prompt, retrieving relevant documents before each call, or fine-tuning a static checkpoint every few months.
But these are workarounds, not solutions. Updating a model's weights directly is risky because it tends to degrade on things it previously knew—a problem researchers call catastrophic forgetting. So the industry built scaffolding instead: bigger context windows, retrieval pipelines, prompt engineering. All of it compensates for the same gap: a model that does not actually learn from doing the job. It just gets handed a longer note each time.
The Real Shift: From Tool to Employee
This is the part worth sitting with. Continual learning is not a backend optimization. It is the difference between renting a tool and hiring an employee.
A tool does the same thing every time, indifferent to how many times you've used it. An employee is supposed to get better with tenure. They carry forward what worked, quietly drop what didn't, and develop judgment that no manual could have given them on day one. That is on-the-job learning, and until now it was something only humans could do.
A continual learning API gives an AI agent the same capacity. Instead of every request starting cold, the agent carries forward a working record of its own experience, refined call after call, the same way a junior analyst becomes a sharp one after a year of real deals, real mistakes, and real corrections.
How It Works: Weights as a Cluster of Experience
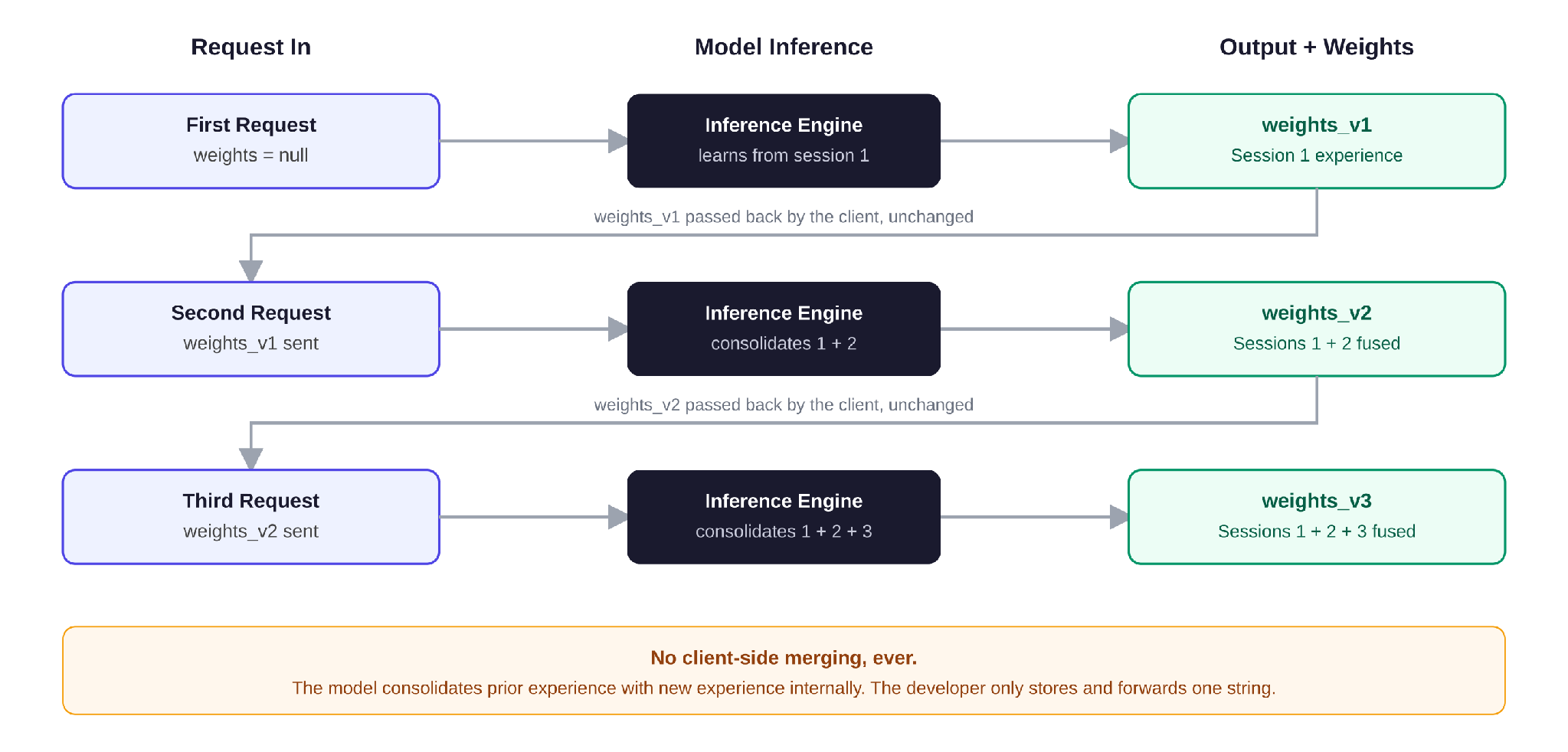
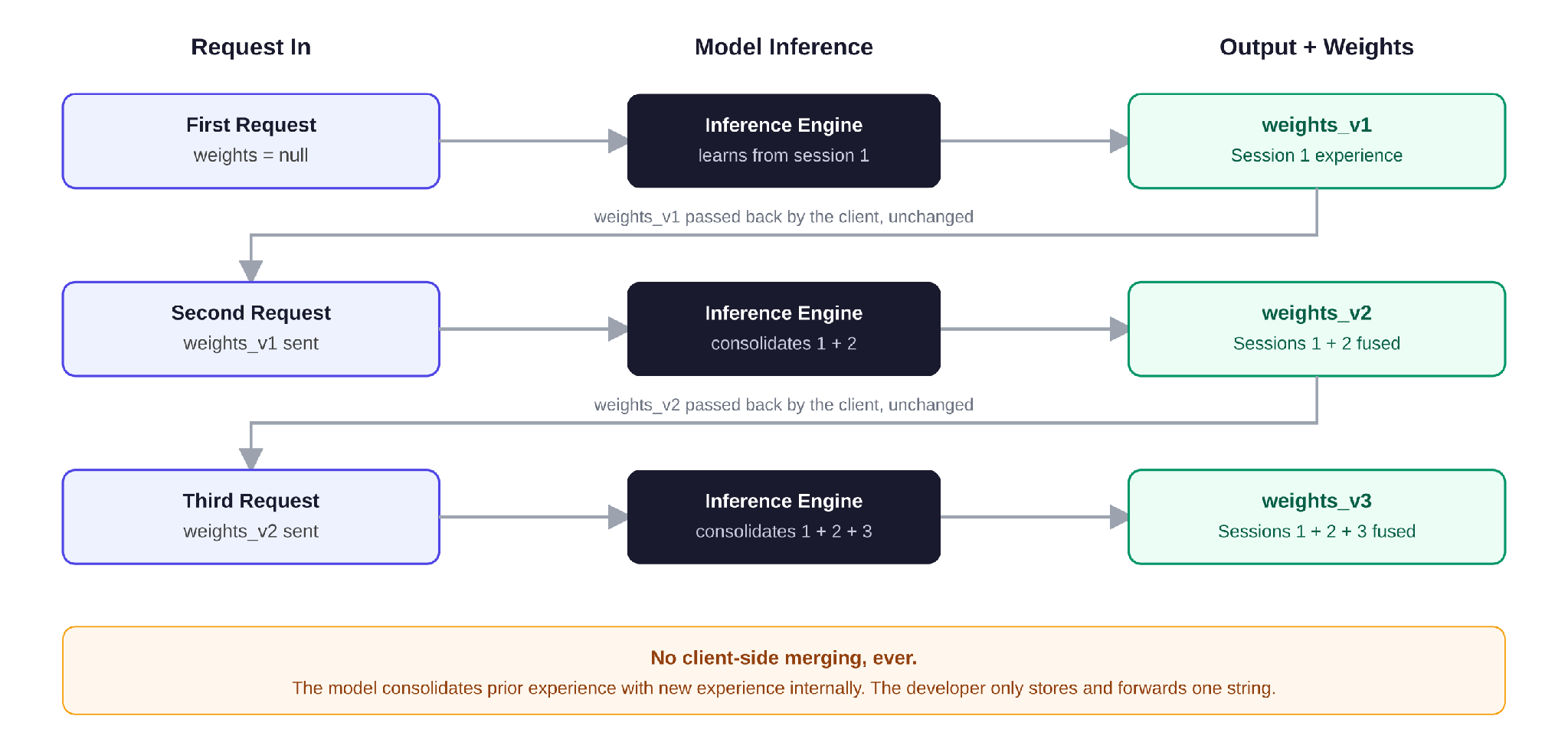
So what is actually being passed between requests? Not a transcript. Not a memory file of past messages. It is the model's own updated weights—the literal parameters that changed as a result of the interaction, serialized into a single string.
Think of weights as a cluster of experience. Every interaction nudges that cluster slightly, the same way a real piece of work nudges a person's instincts. The next request doesn't replay the conversation; it resumes from the place that experience left off.
Why Developers Should Care
- Zero client-side merging: The developer never writes code to combine weights. The model ingests the prior state, runs the new experience through its own inference loop, and hands back the next master checkpoint.
- State serialization, not state tracking: The weights string behaves like a game save file. Store the latest one, send it back, and the model resumes precisely where it left off.
From Preliminary Tasks to Real Judgment
None of this makes static models obsolete. Classification and bounded one-off tasks will likely keep running on stateless APIs for a long time. But the frontier of what people actually want from AI has moved past those tasks.
The interesting problems now are executive decisions, novel research questions, and ambiguous judgment calls—work that rewards a model that has done the job before, gotten it wrong, and adjusted. That is what accumulated weights make possible in a way that a longer prompt never could.
VisionCLv1 · Continual Learning API · Playground API